10 KiB
晨星基金数据爬取
Table of Contents
前言
晨星网,国际权威评级机构 Morningstar 的中国官方网站,所以它的基金数据是很有参考性的,尤其是评级数据
数据爬取
晨星列表数据
爬取晨星网筛选列表,包括基金代码,基金专属代码,基金分类,三年评级,五年评级这些维度等,有了这些基本数据,为了爬取基金详情页,基金筛选等铺好数据基础。
列表爬取数据截图:
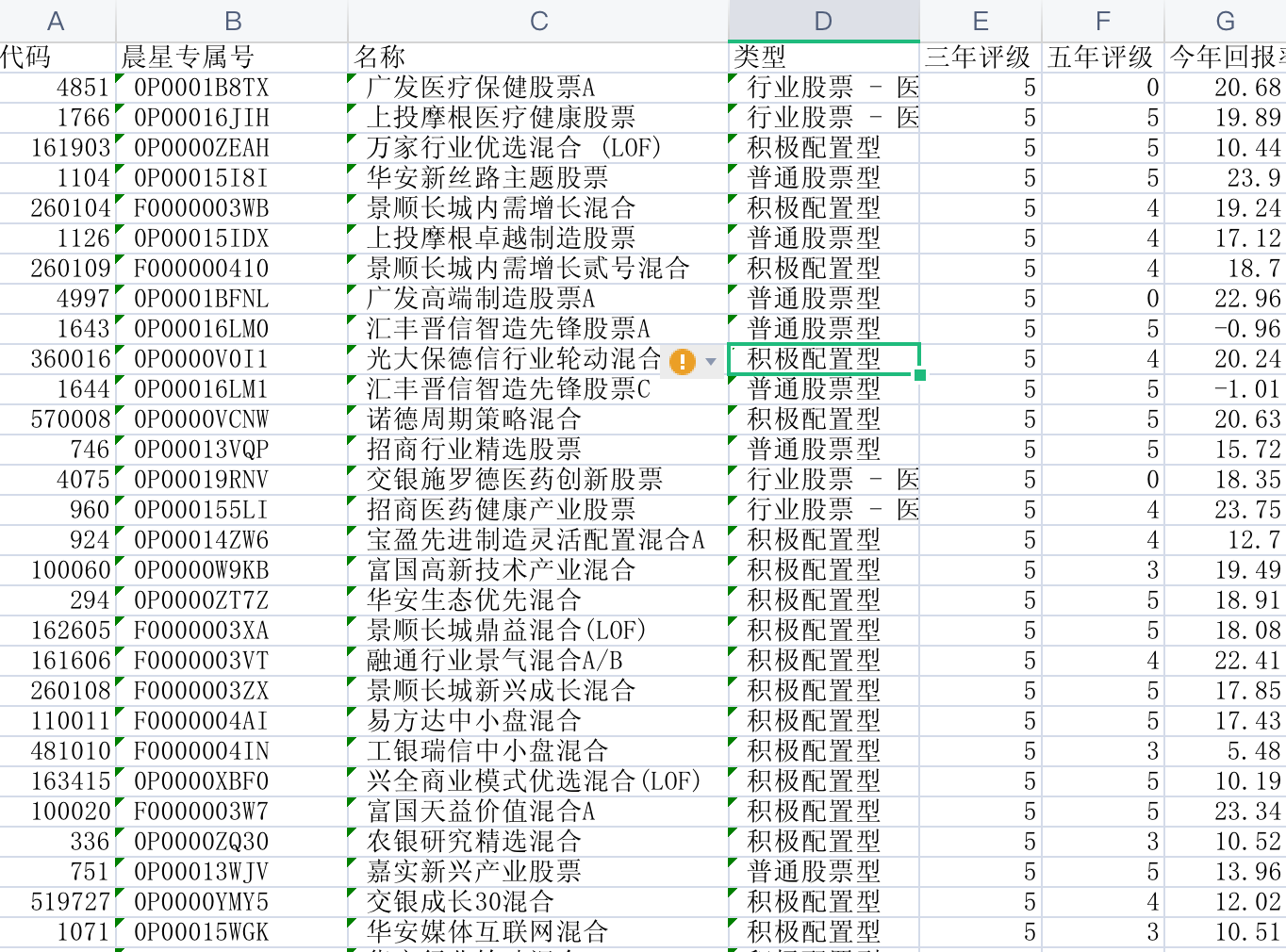
晨星基金详情页数据--固定数据
爬取基金详情页的数据, 根据
晨星列表数据数据,遍历爬取单支基金的详情页数据(包括名称,代码,分类,成立时间,基金公司)等维度,后续还有根据这些数据爬取基金的持仓信息,为后面筛选股票做好进一步铺垫
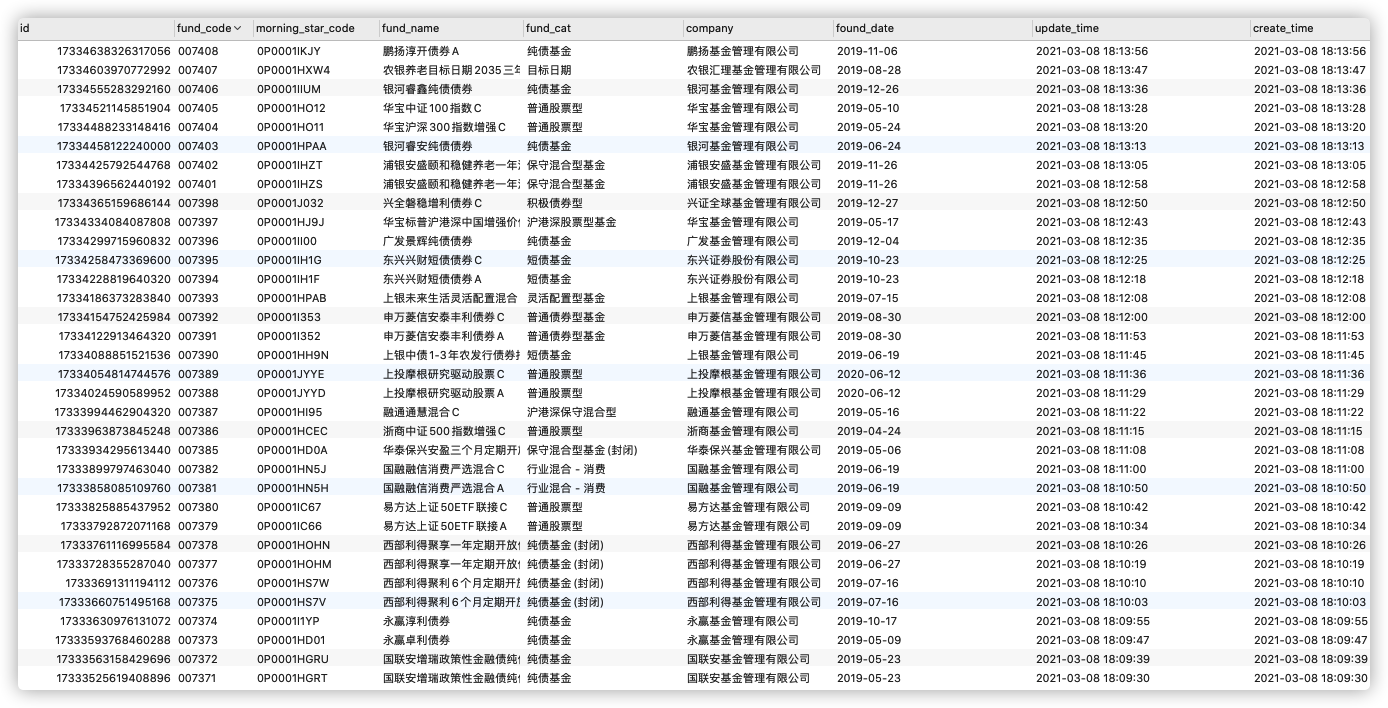
晨星基金详情页数据--季度变动数据
爬取基金详情页的数据, 根据第二部分
晨星基础数据数据,过滤掉货币,纯债基金等不是标的的基金,爬取目标基金的详情页数据(包括总资产,投资风格,各种风险信息,评级,股票,债券持仓比例等)等维度

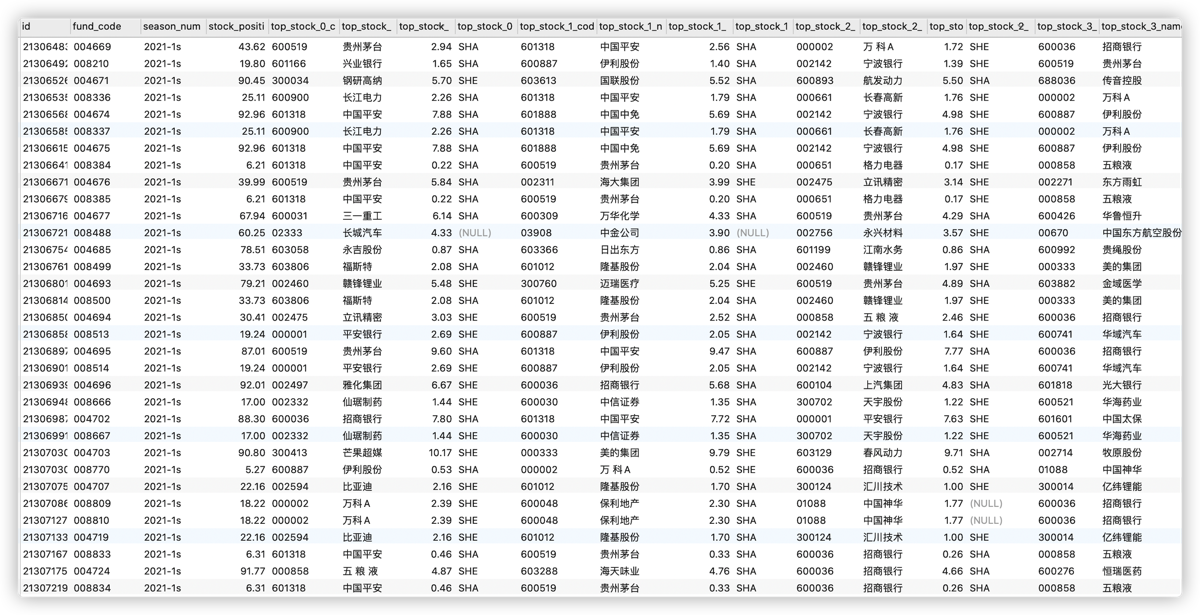
晨星基金详情页数据--十大持仓股票信息
爬取基金详情页的数据, 根据第二部分
晨星基础数据数据,过滤掉没有持有股票的基金,爬取单支基金的十大持仓股票信息(包括每只股票的代码,名称,占比)等维度
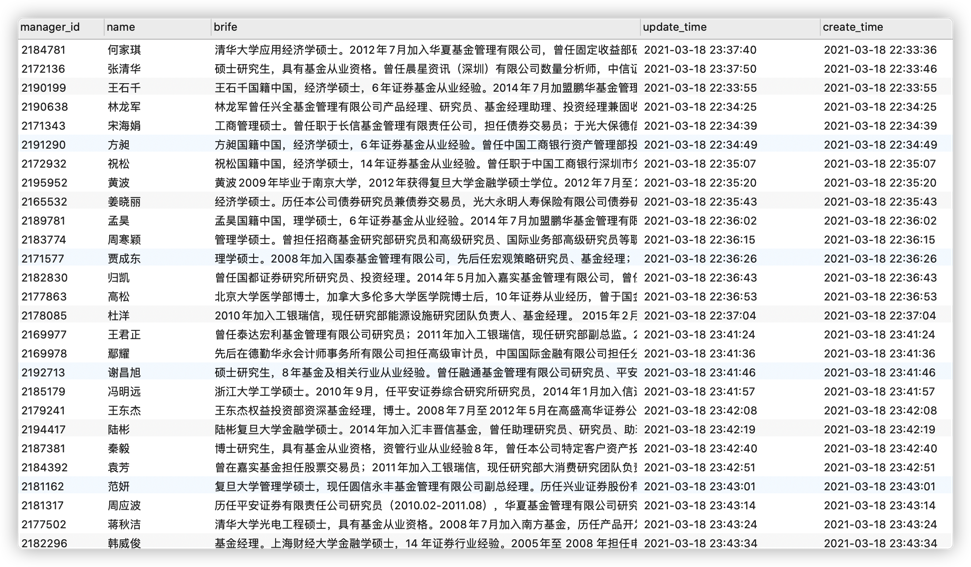
晨星基金经理
爬取基金详情页的数据,据此爬取基金经理数据
技术点
-
selenium模拟登录, 切换分页, 获取html, 最终获取数据 -
部分页面用了
BeautifulSoup解析 HTML -
pandas处理数据 -
数据库mymysql +
sqlalchemy(部分数据用, 部分写原生sql语句) -
工具:
- 通过图片比较获得某一个评级数据 -- 用了
get_star_count_with_np,还提供了备用图片相似度比较get_star_count_with_sewar - 验证码识别使用了
pytesseract(现在已经不用了)
- 通过图片比较获得某一个评级数据 -- 用了
-
多线程爬取
-
其他 -- 一部分数据维度需要其他站点的数据补充,比如检查某一个基金是否已经清算退市, 同类基金的总资产信息等, 直接用request库调用api获取
爬虫流程
selenium模拟登录:- 直接在env文件设置好账号, 密码
可采用验证码识别方式 - 复制已经登录好的账号cookies,设置在env的login_cookie变量中
- 直接在env文件设置好账号, 密码
- 利用
BeautifulSoup解析 html,提取当前页的基金列表信息,存入到 mysql 中,或者追加到 csv 中 (目前仅 acquire_fund_snapshot.py 支持导出 csv) selenium模拟切换分页,重复第二,第三步- 所有的页数据爬取完,退出浏览器
本地运行
安装
pip install -r requirements.txt
本地运行前置条件:
-
安装好 chromedriver 驱动(版本需要和你本地电脑 Chrome 浏览器版本一致),
-
安装 tesseract(识别二维码需要,如果是用 cookies 方式则不需要) 并将 tesseract 加到环境变量下,运行报错的话可能没有安装训练库,可参考https://stackoverflow.com/questions/14800730/tesseract-running-error,如果是需要连接数据库的话,还要配置好表结构 -
如果需要存数据到数据库,需要建好对应表结构,(运行
acquire_fund_snapshot.py可以存在 Excel,其他目前都是存在数据库中) -
从环境参数模板(.env.example)中复制一份文件(.env),修改本地环境变量
cp .env.example .env根据自己情况改环境变量值,例如晨星用户名,密码,执行特定的爬虫脚本
-
运行 --执行
python main.py
input_value = input("请输入下列序号执行操作:\n \
1.“快照” \n \
2.“新基入库”\n \
3.“快照同步新基”\n \
4.“补充基金基础数据”\n \
5.“基金状态归档”\n \
6.“季度信息”\n \
7.“基金持仓股排名”\n \
8.“基金重仓股Top100”\n \
9.“股票持仓基金明细”\n \
10.“股票持仓基金汇总”\n \
11.“高分基金”\n \
12.“组合持仓明细”\n \
输入:")
爬取数据的种子是从快照数据开始的(也就是所有基金列表数据), 有了种子数据之后,再爬取基金基础数据到基金基础表中. 然后根据基金基础表去爬取基金季度一些信息. 获取到数据之后就可以更加自己的需求进行分析和统计了
文件目录介绍
.
├── .env #本地环境配置参数
├── .env.example #环境配置参数模板实例
├── .gitignore
├── README.md
├── requirements.txt
└── src
├── acquire_fund_base.py # 爬取基金基础数据-- 一些不变动的数据,例如成立时间
├── acquire_fund_quarter.py # 爬取基金季度变动 -- 例如持仓数据
├── acquire_fund_snapshot.py # 基金列表快照数据 —— 列表数据
├── fund_info_supplement.py # 执行补充维度清算,总资产信息
├── fund_statistic.py # 基金重仓股分析
├── fund_strategy.py # 高性价比基金筛选
├── sync_fund_base.py # 将快照爬取和基础数据合到一起了
├── assets # 一些静态资源,例如星级图片
│ └── star
│ ├── star0.gif
│ ├── star1.gif
│ ├── star2.gif
│ ├── star3.gif
│ ├── star4.gif
│ ├── star5.gif
│ └── tmp.gif
├── fund_statistic.py # 统计数据
├── config
│ └── env.py # 读取.env配置
├── db
│ └── connect.py # 连接数据库
├── fund_info
│ ├── api.py # api 基金信息爬取,主要是补充crawler不到一些信息
│ ├── crawler.py # 基金页面爬取
│ ├── statistic.py # 基金统计
│ ├── csv.py # 基金存为csv
│ └── supplement.py # 补充或者更新基金清算,总资产维度信息
├── crud # 利用sqlachemly 进行crud
├── models # sqlachemly 表model
├── lib
│ └── mysnowflake.py # 雪花id生成
├── outcome # 数据成果整理子项目
└── utils.py # 一些工具函数,比如登录,设置cookies等
├── __init__.py
├── cookies.py
├── file_op.py
├── index.py
└── login.py
其他
涉及到一些细节有:
验证码识别错误的话,怎么处理- 切换分页如果是最后一页时,怎么处理下一页点击
- 晨星评级是用图片表示,如果转化成数字表示
- 如何保证循环当前页与浏览器当前页一致
- 多线程爬取时,线程锁
- 同名不同类型基金爬取处理
- ...
以上问题,我都做了相对应的处理。
数据汇总&分析
基于上面的数据,简单做了如下数据汇总
性价比高的名单统计
根据基金评级,基金成立时间,基金夏普比例,基金经理从业时间等指标,从几千只股票中选出几十只性比价高的基金,如图所示:
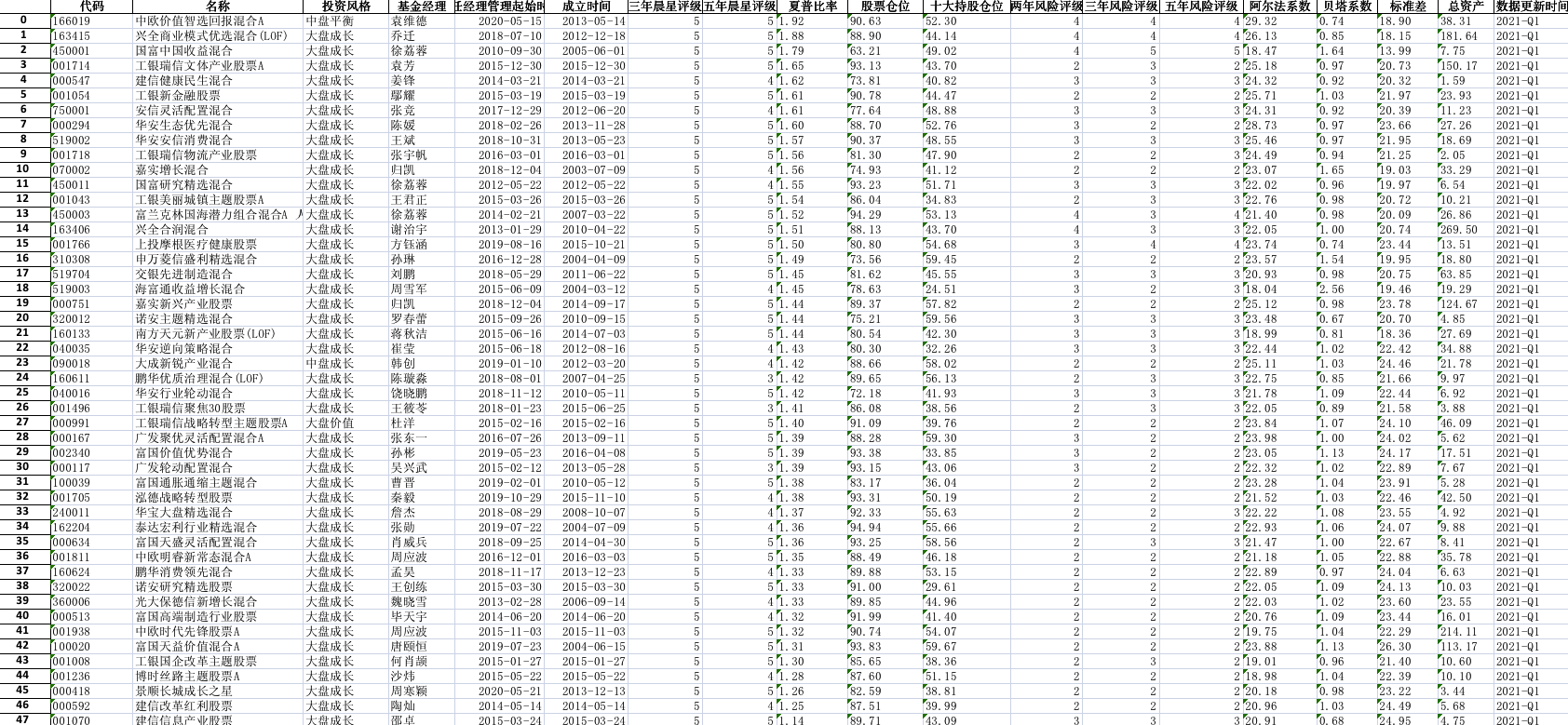
至于”性比价“的定义,大家可以看下面这篇文章 精心整理,给大家汇总一批性价比高的基金名单
基金重仓股
统计股票在这些基金中出现的频率,筛选出 top 50,可用于投资理财辅助,如图:
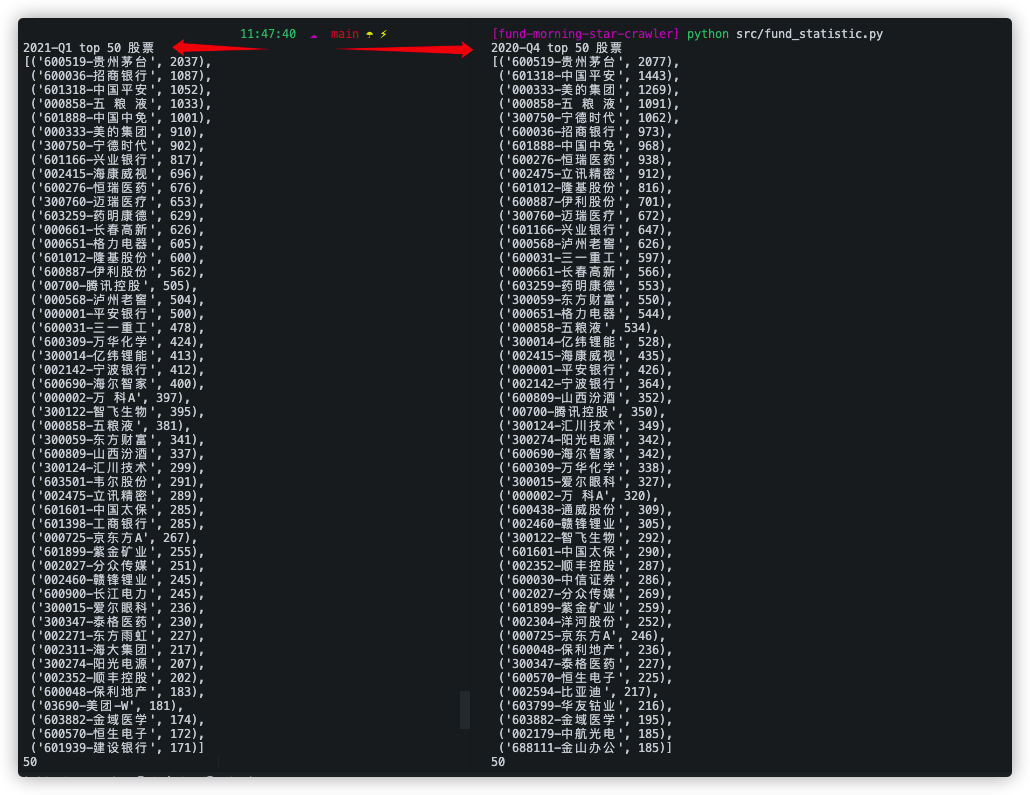
在基于上面的汇总数据,做出如下分析结果,得到 2021-Q1 与 2020-Q4 的基金重仓股 Top50 持仓结果对比,可以分两个维度排序,一个是基金持有个数,一个是持有总市值:
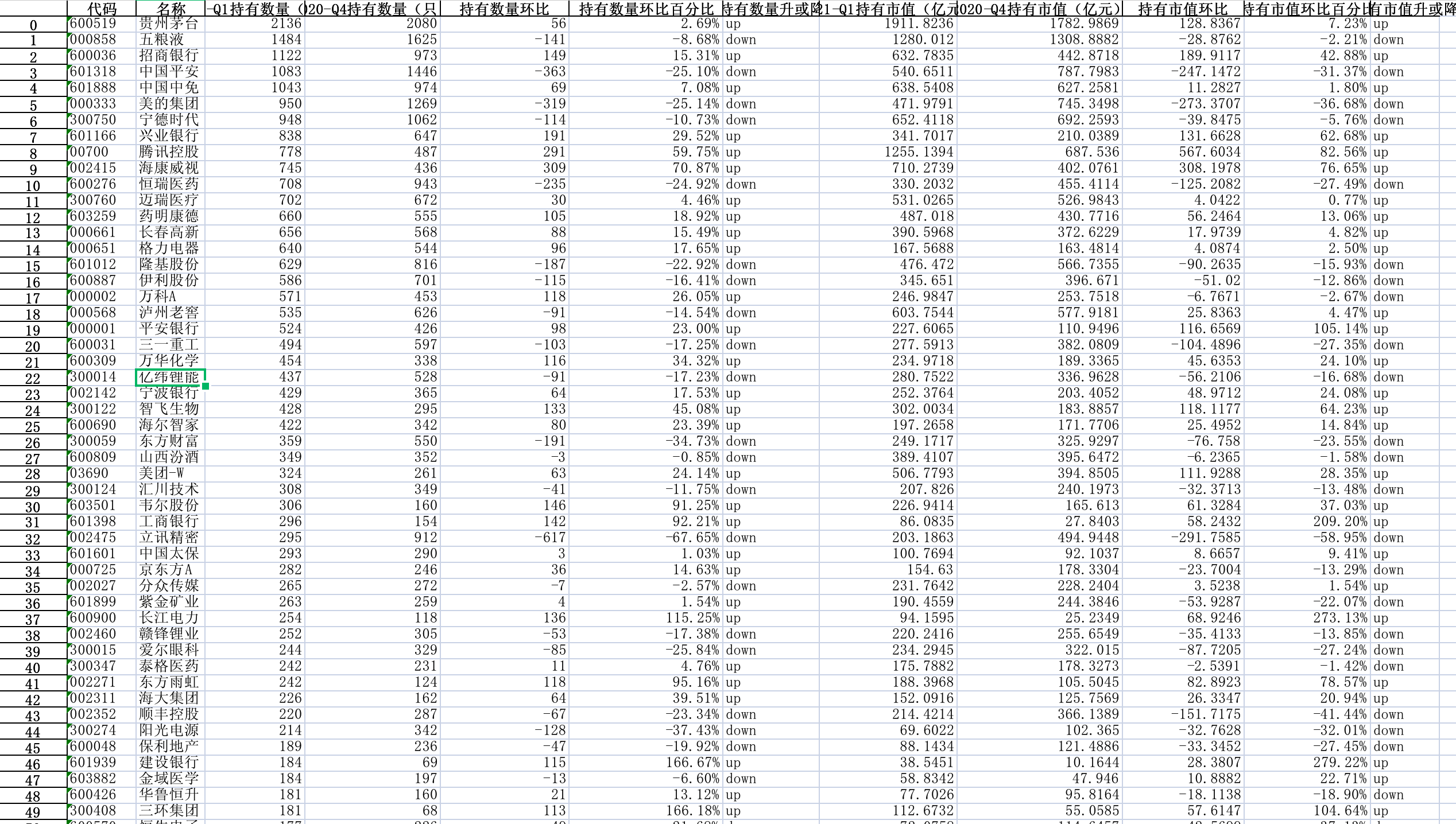
个股基金持仓明细
上面我们知道了基金重仓股排名,我们当然也可以统计某一只股票的基金持仓明细,如图所示,中国平安基金持仓明细:
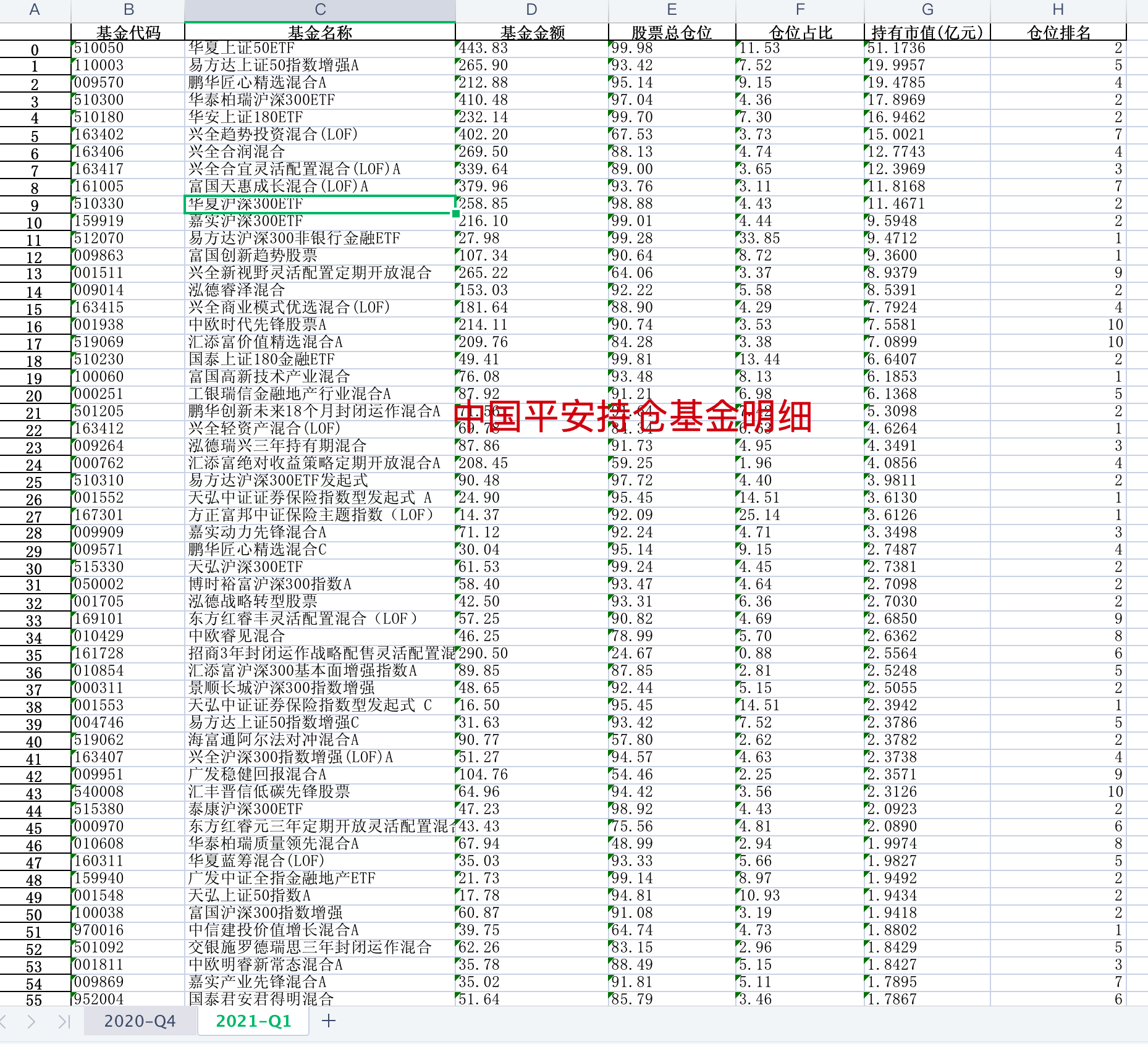
中国平安的基金持仓明细,按基金持有市值排序,其部分数据截图如上
所有的数据统计及分析在 anchor_outcome 子项目下
欢迎扫描下方微信二维码(anchor_data),关注获取更多维度统计数据

如果有问题,有兴趣的话,欢迎提 issue,私聊,star。

另外如果大家感兴趣可转债数据的话欢迎跳到convertible-bond-crawler