You cannot select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
|
|
4 years ago | |
|---|---|---|
| code-record | 4 years ago | |
| output | 4 years ago | |
| screenshot | 4 years ago | |
| src | 4 years ago | |
| .gitignore | 4 years ago | |
| README.md | 4 years ago | |
| requirements.txt | 4 years ago | |
README.md
晨星基金列表数据爬取
前言
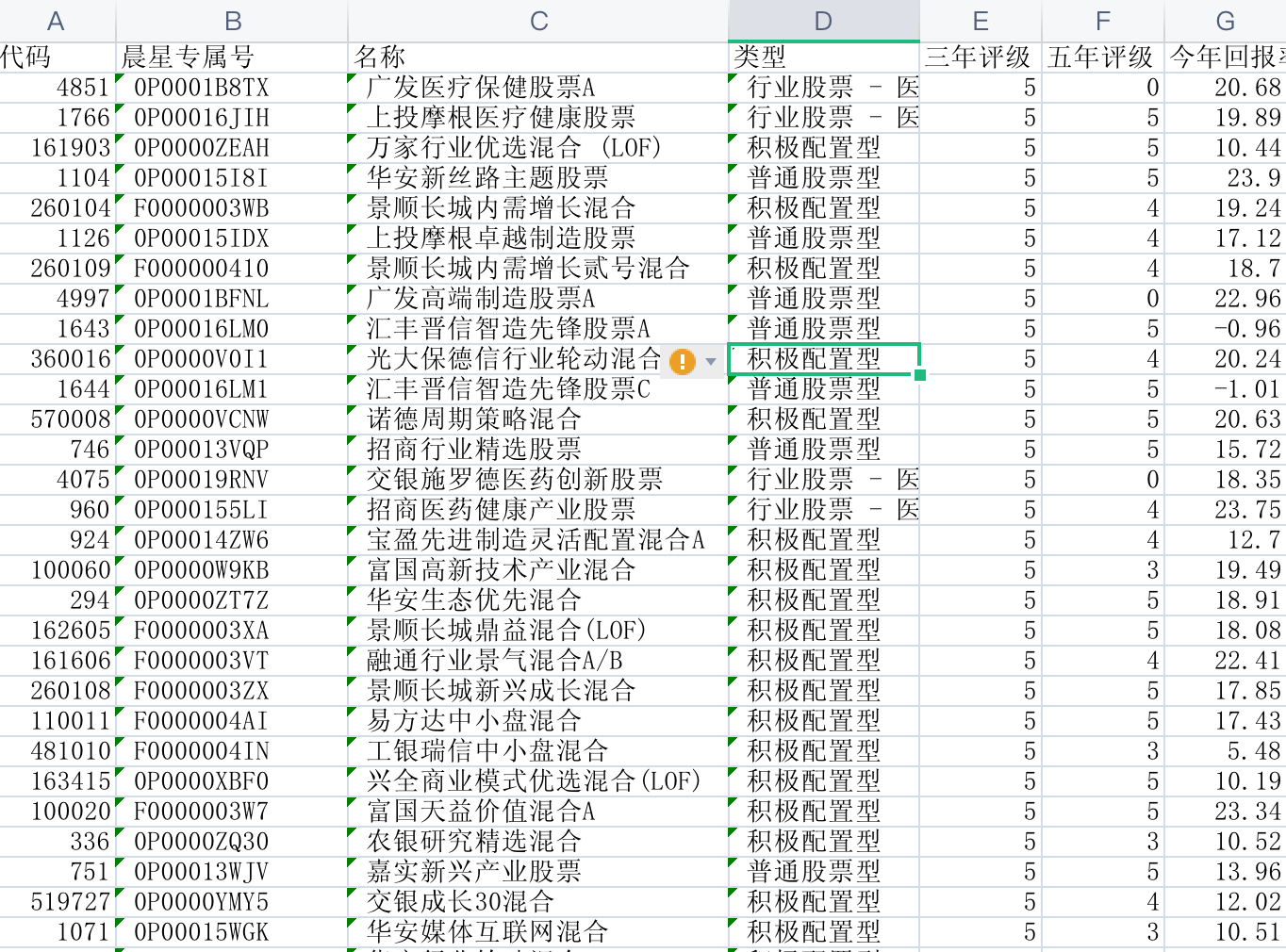
晨星网,国际权威评级机构 Morningstar 的中国官方网站,所以它的基金评级是很有参考性的。该仓库则是爬取晨星网筛选列表,包括基金代码,基金专属代码,基金分类,三年评级,五年评级等,有了这些基本数据,为了爬取基金详情页,基金筛选等铺好数据基础。
基金爬取数据截图:
技术点
selenium模拟登录, 切换分页BeautifulSoup解析 HTMLpandas处理数据- 工具 — 数据库用了
pymysql, id 使用雪花 id,验证码识别使用了pytesseract
爬虫流程
selenium模拟登录:- 可采用验证码识别方式
- 设置已经登录好的账号 cookies
- 利用
BeautifulSoup解析 html,提取当前页的基金列表信息,存入到 mysql 中,或者追加到 csv 中 selenium模拟切换分页,重复第二,第三步- 所有的页数据爬取完,退出浏览器
其他
涉及到一些细节有:
- 验证码识别错误的话,怎么处理
- 切换分页如果是最后一页时,怎么处理下一页点击
- 晨星评级是用图片表示,如果转化成数字表示
- 如何保证循环当前页与浏览器当前页一致
以上问题,我都做了相对应的处理,如果有问题的话,欢迎提 issue,私聊,star。